Reinforcement Learning and Automated Negotiation - A match made in gymnasium
Reinforcement learning is probably one of the most successful ideas in the history of computing. It allowed us lowly computer geeks to build agents that beat or at least rival world champions in chess, go, backgammon, poker, Atari games, and, coolest of all, starcraft. It has its role in the rise of generative AIs like ChatGPT through RLHL (Reinforcement Learning from Human Feedback). Nevertheless, RL is still far from achieving its full potential in the real world. One reason is that the world is messy, much messier than these games with well-defined rules. In this post, I will introduce you to a new game for RL that is directly applicable to the real world. Find a solution today, apply it tomorrow. This new game is technically challenging, just at the edge of the current state of the art in RL and multiagent RL research. If you are looking for a new challenge that is more than dogs vs. cats, look no further.
Why do we need another RL environment
This section goes through the history of RL in games to conclude that we need a new type of environment that is half-way between a Poker game and Atari.
Initial successes of RL in Games
Reinforcement Learning is one of the most successful machine learning techniques for strategic reasoning and game playing problems. It was successfully applied to many games including Chess, Shogi, Diplomacy, and, recently, Sratego. RL shows promise in physical games as well including table tennis, and hockey. Most of these systems were designed to handle a single game. The lessons learned from mastering each of these games did help in mastering the next but usually with new insights added to handle the specific strategic features of the new game.
Generalizing to Multiple Games
Some methods proved successful in multiple games. For example AlphaZero managed to beat specialist agents in Chess, Go, and Shogi. MuZero was able to master Chess, Go, Shogi and $57$ different Atari Games . EfficientZero managed to master $26$ different Atari games. These, and similar systems, are a step toward generality because the same learning algorithm is capable of handling multiple games. Nevertheless, an independent training is needed for each game.
Generalist Agents
Achieving a general game-playing agent is one of the long-term goals of AI research. Recently, more attention was given to RL approaches that allow an agent to play multiple games with a single training on these (or similar) games. For example, Imbala was shown to be able to play multiple Atari games with a single policy.
One step in this direction was General Game Playing (GGP) methods that present the agent with a formal description of a game in a domain-specific language. The agent is supposed to play competently any specifiable game. RL-GGP allowed testing of different RL algorithms in GGP settings. Monte Carlo Q-Learning was shown to achieve high performance on three GGP games (tic-tac-toe, connect-4 and hex). Generalized ALphaZero used RL to play four games (connect-4, breakthrough, babel, and pacman) specified using GGP and was shown to outperform the state of the art method at the time. Research in RL for GGP is usually focused on small games.
Recently, Investigated different approaches to train a single model to play $41$ different Atari games including decision-transformer based sequence modeling, online RL, offline temporal difference, contrastive representation and behavior cloning . They found that decision transformer methods achieved the best performance and scaling but this required training on both expert and non-expert trajectories. But what can you do when you have neither expert nor non-expert trajectories? Enters Generalist Environments.
Generalist Environments
Training specialist agents in a single environment that provides the same challenge every time (e.g. chess, GO) and training a generalist agent for completely unrelated environments (e.g. Atari) are two extremes for which this paper proposes a middle ground. We propose a single environment that encapsulates a large set of related problems by changing the configuration of the environment (i.e. a generalist environment). These problems can be considered individually in independent games or collectively as a single game.
Training a specialist agent for each configuration of a generalist environment is possible but unscalable. Training an agent for all possible configurations of the generalist environment resembles training a generalist agent for multiple games. This type of environment is suitable for training local experts and then learning to activated them as needed for different configurations of the environment which is less explored in RL research. SCML belongs to this class of environments.
The SCML competition
Negotiations and auctions are the most widely used methods for reaching agreements in most real-world businesses. The simplest form of negotiation is bargaining in which partners exchange offers until one is accepted by everyone becoming a binding agreement (a contract). With With the wide-spread adoption of AI by businesses, internal operations of business units are increasingly being automated and automated negotiation between agents representing these business units is a promising direction that is starting to gain the interest of academics and industrialists.
Automated negotiations promise faster more efficient agreements and more win-win deals to everyone. The Automated Negotiation Agents Competition (ANAC) started in 2010 in conjunction with the eights International Joint Conference on Autonomous Agents and Multi-Agent Systems (AAMAS 2010) with the aim of advancing the state of the art in automated negotiation research. The competition succeeded in generating novel research in agent design and expanded to encompass several leagues focusing on different subproblems of automated negotiation.
Since 2019, a new league was added to ANAC called the Supply Chain Management League: SCML. This competition is based on the real-world problem of negotiating agreements in real markets with applications in transportation, industrial manufacturing, energy production and management, and almost anywhere else buyers and sellers exist.
Competitors in the SCM league are required to build an agent that controls a factory embedded in a simulated market. Besides controlling production, the agent should negotiate with other agents representing suppliers and consumers to secure supplies and sales. The score of a competitor is the median profit accumulated by all instantiations of her agent in thousands of simulations with varying configurations.
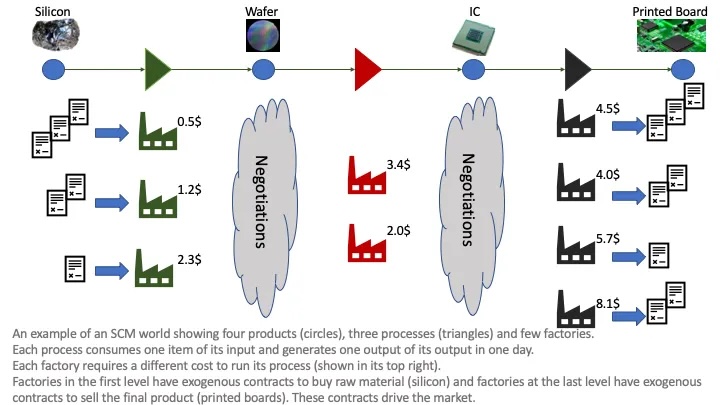
Each instantiation of the SCML simulation defines a multilateral general-sum incomplete-information stochastic game that is determined by the static information (configuration). Agents can be designed/trained to work in a specific configuration (specialist agents), across classes of configurations with common features (e.g. simulations in which the agent is a supplier or simulations with specific number of factories in each production level) leading to local experts, or for any SCML instantiation (generalist agents). That is what makes SCML a generalist environment
The main challenge faced by agents in SCML is a repeated concurrent many-to-many negotiation problem. The agent is negotiating concurrently with all its suppliers and consumers trying to maximize its profit in the current step while keeping an eye in maximizing future profits that can only be generating by future negotiations with the same partners.
You can find a full description of the game here.
How to participate
To participate on this competition, you just need to install a single package (well may be two):
pip install scml
A nice companion is a streamlit visualizer that can help you debug your code:
pip install scml-vis
You can then just download the template for a classic agent or an RL agent and start hacking away.
RL for SCML
We developed a gymnasium environment that exposes RL as a standard Gymnasium Environment. This SCML environment can be used for both RL and MARL. For simplicity of exposition, we only consider single-agent RL in this paper in which the RL agent is allowed to control a single factory (any factory) in each simulation. Extension to multi-agent RL is straightforward.
SCML exemplifies some of the main challenges of real-world applications of RL:
- High dimensional state space: The amount of information available to the agent about the environment and other agents is huge.
- System constraints that can never be violated: The agent should never allow itself to go bankrupt.
- Stochastic systems with partial observability: The SCML simulation is always stochastic because exogenous contracts are sampled randomly (albeit from a known distribution) every period. Moreover, the agent cannot observe any private information of other agents in the environment.
- Poorly specified reward functions: The profit calculation method described in Section X defines the change in the agent’s balance in a given period. This is not the utility of the agent because it does not take into account the effect of its carried inventory and the change in future partner behavior based on the agent’s action during this period.
Moreover, SCML also exhibits the problem of state-space ambiguity discussed in the introduction that plagues many real-world deployments of RL in business applications. Given the richness of information available to the agent, the designer can decide whether or not to use each individual piece of information as a part of the agent’s observation. Moreover, some of the static information (configuration) may be used to construct different training contexts to train multiple RL agents for specific situations, a commonly used strategy in real-world deployments of RL.
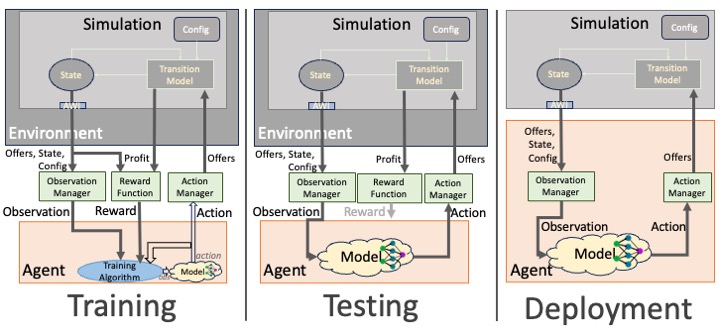
- The Environment: The SCML environment presents an SCML simulation to the agent as a standard RL problem. (Footnote: SCML is available as a standard Farama gymnasium environment https://gym.openai.com/, making it compatible with most RL and MARL environments including SB3, RLLib, tf-agents, and torch-RL.)
- The Agent: The RL agent controls a single SCML factory receiving observations from the environment and returning actions as counter-offers that are passed to the agent’s suppliers and consumers inhabiting the simulation within the environment.
- Adapters: There are three adapters that mediate the agent-environment interaction:
- Observation Manager: Selects information to be observed by the agent and encodes it in a suitable RL format (i.e., discrete or continuous numeric values).
- Reward Function: The only signal directly provided to the agent is profit calculated per period. This signal is sparse Additionally, it doesn’t reflect the value of inventory or effects on future negotiations. The designer can use this component to provide a more informative reward to the agent (i.e., reward shaping).
- Action Manager: Responsible for decoding agent-generated actions into valid counter-offers for the simulation. Note: We provide a universal action manager usable with an SCML environment creating a continuous or discrete action space as needed.
Contextual Training and Deployment
As discussed earlier, each SCML configuration defines a unique simulation environment with some shared characteristic with all other simulations (e.g. buyers always prefer lower prices). For example, a $L_0$-agent in a two-levels production graph with $10$ competitors and $2$ consumers is facing a very different market compared with another $L_0$-agent with 2 consumers and $10$ competitors.
It is unlikely that a single policy or trained model can achieve adequate performance in all possible SCML configurations. Nevertheless, it is impractical to train a dedicated policy for each possible configuration.
We define a Training Context as a data-structure the defines a set of configurations, an observation manager, an action manager and, optionally, a reward function. In the RL implementation of SCML, environments receive their configuration for simulation generation from a context object. Policies are trained for a specific context (i.e. using environments that share the same context). When deployed, the agent receives a set of contexts and associated trained policies (models). It checks the actual information of the simulation it finds itself inhabiting and selects the most similar context activating its corresponding policy, observation manager and action manager. This process is shown in the following diagram:
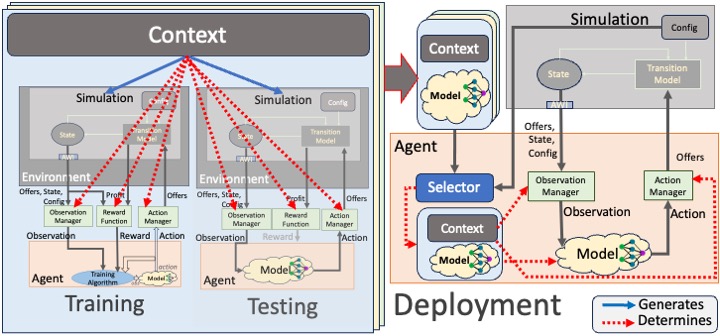
The process of creating an RL solution for SCML involves the following steps:
-
Define Contexts: Establish training contexts that capture the various market conditions and configurations your agent might encounter within the SCML simulation.
-
Design Adapters (Per Context): For each context, specify:
- Observation Manager: Function to select and encode relevant information for the agent’s state representation.
- Action Manager: Function to translate the agent’s actions into valid counter-offers within the simulation.
- Reward Function: Method to calculate informative rewards that guide the agent’s learning (consider going beyond immediate profit).
-
Train Policies (Per Context): Use your preferred RL algorithm to train a policy for each defined context.
-
Deployment and Context Switching:
- Equip the agent with the trained policies and their associated contexts.
- During deployment, have the agent analyze the current simulation to select the most appropriate context, activating the corresponding policy and adapters.
Illustrative Pseudocode:
def create_rl_solution(scml_env):
contexts = define_contexts() # Function to create list of Training Contexts
for context in contexts:
observation_manager = context.observation_manager
action_manager = context.action_manager
reward_function = context.reward_function
policy = train_policy(scml_env, observation_manager, action_manager, reward_function)
return contexts, policies
def deploy_agent(agent, scml_env, contexts, policies):
while True: # Main simulation loop
current_sim_config = scml_env.get_configuration()
best_context = find_matching_context(current_sim_config, contexts)
observation = best_context.observation_manager(scml_env)
action = best_context.policy(observation)
counter_offer = best_context.action_manager(action)
scml_env.step(counter_offer)
...
Take-away message
- SCML provides a new and important type of environment for developing real-world relevant RL and MARL solutions.
- The SCML competition provides the perfect opportunity to develop RL-based solutions to this problem. Other than the joy of solving a new problem, the competition provides monetary prizes, and even travel scholarships (for selected students) to attend AAMAS 2024, one of the top AI conferences in the world.
- Everything you need to start working on this problem is available at the competition website.